A distributed database (DDB) is a collection of multiple logically interrelated databases distributed over a computer network. A distributed database management system (DDBMS) is the software that manages the DDB and provides an access mechanism that makes the distribution transparent to the users. The distributed database DDB and distributed database management system DDBMS together is called distributed database system (DDBS).
A distributed database refers to the database system that is spread across multiple computers or nodes connected by a computer network. In this type of database, the data is stored in a distributed manner with each node holding a subset of overall data. The nodes can be located in the same physical location or geographically dispersed.
The primary goal of a distributed database is to provide scalability, fault tolerance, and improved performance compared to centralized databases. A distributed database can handle large data volumes and support higher levels of concurrent users.
Fig: Distributed Database
Characteristics of Distributed Database System
A collection of logically related shared data
The data is split into a number of fragments
Fragments may be replicated
Fragments/replicas are allocated to sites
The sites are linked by a communications network
The data at each site is under the control of a DBMS
The DBMS at each site can handle local applications autonomously
Each DBMS participates in at least one global application
Components of Distributed Database System
The distributed database system consists of several essential components:
Computer workstations or remote devices (Sites or nodes) that form the computer network system. The distributed database system must be independent of the computer system hardware.
Network hardware and software components that reside in each workstation or device. The network components allow all sites to interact and exchange data.
Communications media that carry the data from one node to another. The DBMS must be communications media independent, that is, it must be able to support several types of communications media.
The transaction processor, which is the software component found in each computer or device that requests data. The transaction processor receives and processes the application's data request, remote and local. The transaction processor is also known as or the .
The data processor, which is the software component residing on each computer or device that stores and retrieves data located at the site. The data processor is also known as data manager. A data processor may be even via centralized DBMS.
Advantages of DDBS
Reflects organizational structure: Many organizations are naturally distributed over several locations.
Improved shareability and local autonomy: Users at one site can access data stored on other sites. Data can be placed at the site close to the users who normally use the data. In this way, users have local control of data and they can consequently establish and enforce local policies regarding the use of this data.
Improved availability: A computer failure terminates the operation of the DBMS in the centralized DBMS. However, a failure at one site of the DDBMS or failure of a communication link making some sites inaccessible does not make the entire system inoperable. Distributed DBMS are designed to continue to function despite such failures. If a single node fails, the system may be able to reroute the failed node's request to another site.
Improved reliability: Because the data may be replicated so that it exists at more than one site, the failure of a node or communication link does not necessarily make the data inaccessible.
Improved performance: As the data is located near the site of greatest demand and given the inherent parallelism of distributed DBMS, speed of database access may be better than that achievable for a remote centralized database. Furthermore, since each site handles only a part of the entire database, there may not be the same contention for CPU and I/O services as characterized by centralized DBMS.
Economics: The potential cost saving occurs where databases are geographically remote and the applications require access to distributed data.
Modular growth: It is much easier to handle expansion. New sites can be added to the network without affecting the operation of other sites.
Disadvantages of DDBS
Complexity: It is more complex than a centralized DBMS. The fact that data can be replicated also adds an extra level of complexity to the distributed DBMS. If the software does not handle the data replication adequately, there will be degradation in availability, reliability, and performance compared to the centralized system. And those advantages will become disadvantages.
Cost: Increased complexity means that we can expect the procurement and maintenance cost per DBMS to be higher than those for the centralized DBMS. A distributed DBMS requires additional hardware to establish a network between the sites.
Security: In a centralized system, access to data can be easily controlled. However, in a distributed DBMS, not only does access to replicated data have to be controlled in multiple locations, but the network itself has to be made secure.
Integrity control more difficult: In a distributed DBMS, the communication and processing costs that are required for enforcing integrity constraints may be prohibitive.
Lack of standards: Although distributed DBMS depend on effective communication, we are now only starting to see the appearance of standard communication and data access protocol. This lack of standards has significantly limited the potential of distributed DBMS.
Lack of experience: The general propose distributed DBMS have not been widely accepted, although many other protocols and problems are well understood. We don't yet have the same level of experience in the industry as we have with centralized DBMS.
Database design more complex: The design of a distributed database has to take account of fragmentation of data, allocation of fragments to specific sites, and data replication.
Data Fragmentation
Data fragmentation refers to the process of dividing a database's tables or relations into smaller, more manageable pieces called fragments. These fragments are distributed across different nodes (locations) in the distributed database system. The goal of the fragmentation is to improve performance and efficiency by distributing data across multiple nodes. It allows for parallelism and reduces the amount of data that needs to be transmitted over the network for query processing. It also provides better disaster recovery.
Types of Fragmentation
Fragmentation can be of three types:
Vertical fragmentation
Horizontal fragmentation
Hybrid fragmentation
Fragmentation should be done in a way so that the original table can be reconstructed from the fragments. This is needed so that the original table can be reconstructed from the fragments whenever required. This requirement is called reconstructiveness.
Advantages of Fragmentation
Since data is stored close to the site of users, efficiency of the database system is increased.
Local query optimization techniques are sufficient for most queries since data is locally available.
Since irrelevant data is not available at the site, security and privacy of the database system can be maintained.
Disadvantages of Fragmentation
When data from different fragments are required, the access expense may be very high.
In case of recursive fragmentation, the job of reconstruction will need expensive techniques.
Lack of backup copies of data in different sites may render the database ineffective in case of failure of a site.
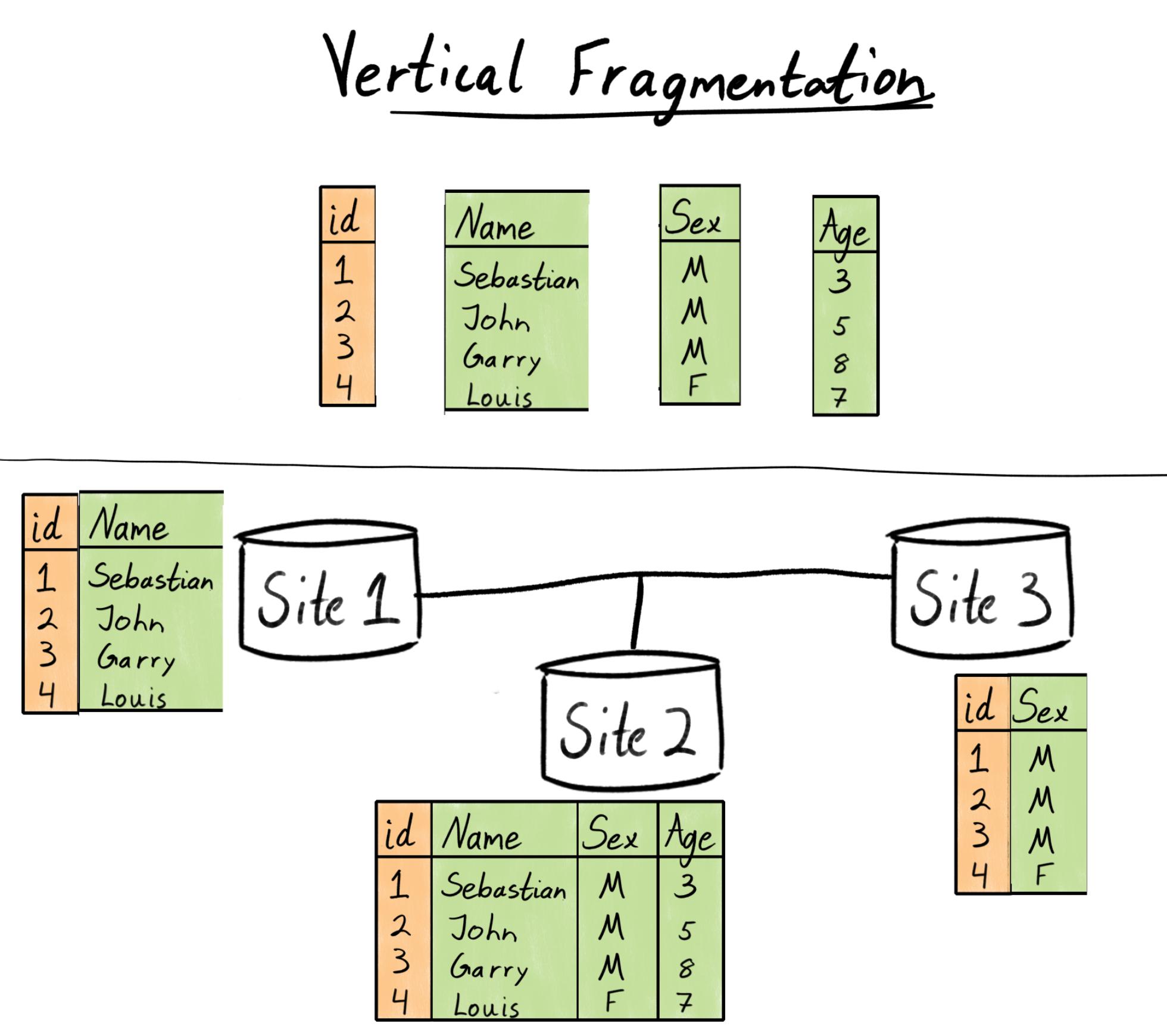
Vertical Fragmentation
Vertical fragmentation design involves dividing a table into subsets of columns or attributes. In vertical fragmentation, the fields or columns of a table are grouped into fragments. In order to maintain reconstructiveness, each fragment should contain the primary key fields of the table. Vertical fragmentation can be used to enforce privacy of data.
Fig: Vertical Fragmentation
Example
Let us consider that college management system keeps record of all registered students in a student table having the following schema.
Student
Stu_id
Stu_name
Stu_address
Dept_id
10
Maya
Palpa
1
11
Abhin
KTM
2
12
Arnav
KTM
1
Now, the address details are maintained in the admin section. In this case, the designer will fragment the database as follows:
CREATE TABLE stu_address AS
SELECT Stu_id, Stu_address
FROM Student;
By executing above query, we get the following result.
Stu_address
Stu_id
Stu_address
10
Palpa
11
KTM
12
KTM
13
Palpa
Vertical Data Fragmentation of Student Table
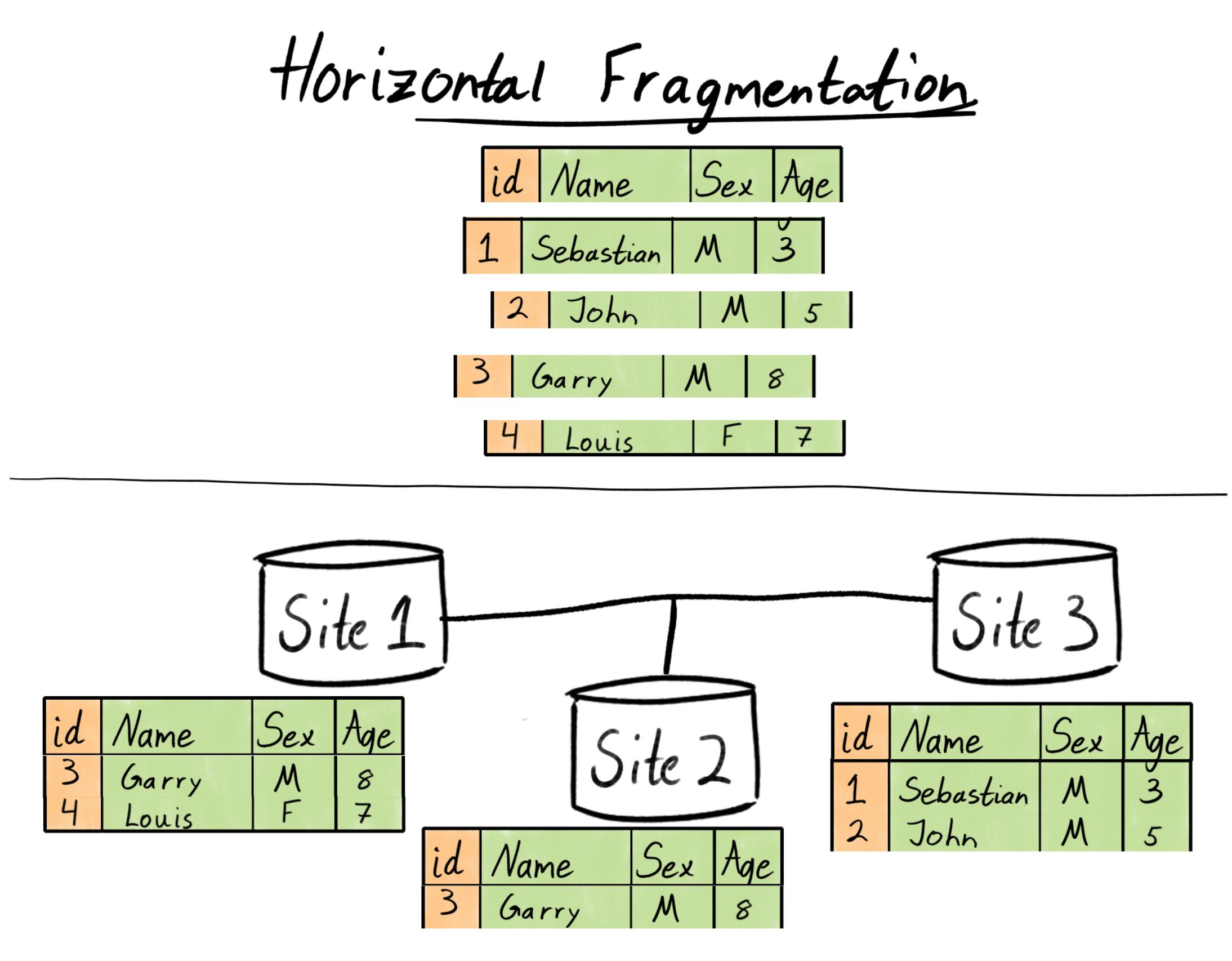
Horizontal Fragmentation
Horizontal fragmentation involves dividing a table into subsets of rows or tuples. Each subset is stored on a different node. Horizontal fragmentation groups the tuples of a table in accordance to values of one or more fields. Horizontal fragmentation should also conform to the rule of reconstructiveness. Each horizontal fragment must have all columns of the original base table.
Fig: Horizontal Fragmentation
Example
In the STUDENT schema, if the details of all students of department 1 need to be maintained at the respective faculty, then the designer will horizontally fragment the database as follows:
CREATE TABLE Department AS
SELECT *
FROM STUDENT
WHERE dept_id = 1;
By executing the above query, we get the following result:
Department
Stu_id
Stu_name
Stu_address
Dept_id
10
Maya
Palpa
1
12
Arnav
Kathmandu
1
Horizontal Fragmentation of Student table
Hybrid Fragmentation
Hybrid fragmentation is a combination of both vertical and horizontal fragmentation techniques. It involves dividing a table into subsets of rows and columns, which are then distributed across different nodes. This is the most flexible fragmentation technique since it generates fragments with minimal extraneous information. However, reconstruction of the original table is often an expensive task.
Fig: Hybrid Fragmentation
Approaches to Hybrid Fragmentation
Hybrid fragmentation can be done in two alternative ways:
It first generates a set of horizontal fragments, then generates vertical fragments from one or more of the horizontal fragments.
It first generates a set of vertical fragments, then generates horizontal fragments from one or more of the vertical fragments.
Example
CREATE TABLE Hybrid AS
SELECT Stu_id, Stu_name
FROM STUDENT
WHERE Stu_id = 12;
By executing the above query, we get the following result:
Hybrid
Stu_id
Stu_name
12
Arnav
Hybrid Fragmentation of Student table
Data Replication
Data replication is the process of creating and maintaining multiple copies of the same data across different nodes in a distributed system. Each copy of the data is known as a replica. It is an important mechanism because it enables organizations to provide users with access to current data where and when they need it. It is intended to increase the fault tolerance of a system such that if one replica fails, another can continue to serve queries or requests.
Purpose
System Availability: Distributed database system removes single point of failure by replicating data so that data items are accessible from multiple sites. Consequently, even when some sites are down, data may be accessible from other sites.
Performance: Replication enables us to locate the data closer to the access point, thereby localizing most of the access. That contributes to reduction in response time.
Scalability: As the system grows geographically and in terms of the number of sites, consequently in terms of the number of access requests, replication allows for a way to support this growth with acceptable response time.
Application requirements: Replication may be dictated by the applications which may wish to maintain multiple data copies as part of their operational specification.
Advantages
Reliability: Database system continues to work since the copy is available at another site if in case of failure of any site.
Reduction in network load: Since local copies of data are available, query processing can be done with reduced network usage, particularly during prime hours. Data updating can be done at non-prime hours.
Quicker response: Availability of local copies of data ensures quick query processing and consequently quick response time.
Simpler transactions: Transactions require a small number of joins of tables located at different sites and minimal coordination across the network.
Disadvantages of Data Replication
Increased storage requirements: Maintaining multiple copies of data is associated with increased storage cost.
Increased cost and complexity of data updating: Each time a data item is updated, the update needs to be reflected in all copies of the data at different sites. This requires complex synchronization techniques and protocols.
Undesirable application - database coupling: If complex update mechanisms are not used, the removal of data inconsistency requires complex coordination at application level. This results in undesirable application-database coupling.
Challenges
Placement of Replicas
The major challenge in replication is where to put all the replicas. There are three places to put replicas:
Permanent replicas: It consists of a cluster of servers that may be geographically dispersed.
Server-initiated replicas: Server-initiated caches include placing replicas in the hosting servers and server caches.
Client-initiated replicas: In Web Browser Cache.
Propagation of Updates Among Replicas
Push-based propagation: A replica A's update occurs, pushes the updates to all other replicas.
Pull-based propagation: A replicas requests another replica to send the newest data it has.
Lack of Consistency
If a copy is modified, the copy becomes inconsistent from the rest of the copies. It takes some time for all the copies to be consistent.
Data Allocation
Data allocation refers to the placement of data and processing task takers to different nodes in a distributed database system. It involves determining how to distribute data and workload to achieve optimal performance and resource utilization. The choice of sites and degree of replication depends on the performance and availability of goals of the system and on the types and frequencies of transactions submitted at these sites.
Strategies for Data Allocation
There are four alternative strategies regarding placement of data which are as follows.
Centralized
This strategy consists of a single database and DBMS stored at one site with users distributed across the network. Locality of reference is at its lowest as all sites, except the central site, have to use the network for all data accesses. This also means that communication costs are high, reliability and availability are low, as the failure of the central site results in the loss of the entire database system.
Fragmented or Partitioned
This strategy partitions the database into different fragments with each fragment assigned to one site. If data items are located at the site where they are used most frequently, locality of reference is high. As there is no replication, storage costs are low. Similarly, reliability and availability are low, although they are higher than in the centralized case as the failure of a site results in the loss of only that site's data. Performance should be good and communication cost low if the distribution is designed properly.
Complete Replication
This strategy consists of maintaining a complete copy of a database at each site. Therefore, locality of reference, reliability and availability and performance are maximized. However, storage costs and communication costs for updates are the most expensive. To overcome some of these problems, snapshots are sometimes used. A snapshot is a copy of the data at a given time. These copies are updated periodically, for example hourly or weekly, so they may or may not be always up-to-date. Snapshots are also sometimes used to implement views in distributed databases to improve the time it takes to perform a database operation on a view.
Selective Replication
This strategy is a combination of fragmentation, replication and centralization. Some data items are fragmented to achieve high locality of reference, and others that are used at many sites are not frequently updated and replicated. Otherwise, the data items are centralized. The objective of this strategy is to have all the advantages of other approaches but none of the disadvantages. This is the most common used strategy because of its flexibility.
Types of Distributed Database Systems
Homogeneous Distributed Database System
In a homogeneous distributed database system, all participating nodes use the same DBMS software. The underlying schema are typically replicated across multiple nodes, and each node can process local transactions and queries. Homogeneous systems provide high availability, fault tolerance, and load balancing.
Types:
Autonomous – Each database is independent and functions on its own. They are integrated by a controlling application and use messages to share updates.
Non-autonomous – Data is distributed across homogeneous nodes, and a central DBMS coordinates data updates across sites.
Heterogeneous Distributed Database System
In heterogeneous distributed database systems, different nodes may use different DBMS software or have varying data models. These systems often require a middleware layer or data integration tools to facilitate communication and data exchange between different nodes. Heterogeneous systems are useful when integrating existing databases from multiple sources or different data models.
Types:
Federated – Independent in nature and integrates together as a single database.
Unfederated – Central coordinating module is used to access database.
Distributed Database Architectures
The architectures are generally developed on three parameters:
Distribution – It states the physical distribution of data across different sites.
Autonomy – It indicates the distribution of control of DBMS and degree to which each DBMS can operate independently.
Heterogeneity – Refers to uniformity or dissimilarity of data model, system components, and databases.
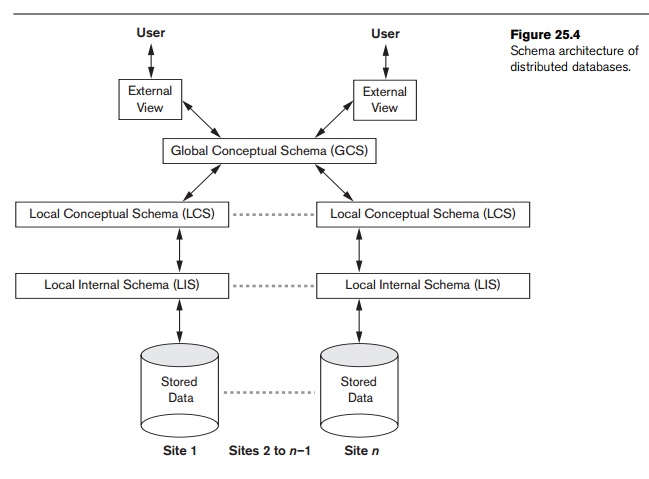
General Architecture of Pure Distributed Databases
Fig: Schema architecture of pure distributed databases
This architecture has four levels of schema:
External view or schema (EV or ES): Presents user view of data. Different users may have different externam schema. Hides distribution, fragmentation and replication details.
Global conceptual schema (GCS): Presents a global logical view of data which provides network transparency. Integrates all data across sites into single schema.
Local conceptual schema (LCS): Depicts logical data organization at each site. Describes how data is logically organized locally.
Local internal schema (LTS): Presents physical data organization at each site. Includes file organization, indexes and access paths. Site-specific and hidden from user.
Federated Database Schema Architecture
Local schema: Conceptual schema, full database definition of a local database.
Component schema: Derived by translating local schema into common data model.
Export schema: Represents the subset of a component schema. Protects local autonomy and security.
Federated schema: Global schema which is the result of integrating all the shareable expert schemas. Provides unified global view.
External schema: Defines the schema for a user group or an application.
Fig: Federated Schema Architecture
Three-Tier Client-Server Architecture
Presentation layer (client): Provides UI and interacts with user, handles user inputs/outputs, and navigates by accepting user commands and displays needed information in static or dynamic web pages.
Application layer (business layer): Programs the application logic, additional functionalities are handled here like security, ID verification, and other few functions. It interacts with one or more databases or data sources as needed by connecting to the database using ODBC, JDBC, SQL/CLI or other database access techniques.
Database server: Handles queries and updates requests from application layer, processes the request, and sends back results.
Introduction to NoSQL System
NoSQL systems are alternative to traditional relational databases, empowering developers and organizations to efficiently handle large-scale data and build scalable, flexible, and high-performance applications.
A NoSQL database, which stands for non-SQL or non-relational, is a database that allows for data storage and retrieval. Unlike traditional SQL based databases that use rigid tabular schemas, NoSQL databases store data usign flexible models such as documents, graphs, key-value etc. It works with billions of data and is easy to scale. NoSQL is used for big data and real-time web apps. It is efficient to use by the organizations which deals with huge volumes of data.
The Need for NoSQL
The system response time becomes slow when RDBMS is used for massive volumes of data. To resolve this problem, we could scale up our system by upgrading our existing hardware. This process is expensive.
The alternative for this issue is to distribute database load on multiple hosts whenever the load increases. This method is known as scaling out. NoSQL database is non-relational, so it scales out better than relational databases as they are designed with web applications in mind.
Characteristics or Advantages of NoSQL Databases
Scalability:
NoSQL databases are designed to support horizontal scalability, which allows organizations to easily add resources and increase storage and processing capacity by using commodity hardware. This scaling can be done quickly and in a non-disruptive manner. Unlike traditional relational database management systems (RDBMS), NoSQL databases reduce or eliminate the need for complex and costly manual sharding, thereby lowering management overhead and improving scalability efficiency.
Performance:
NoSQL databases achieve high performance by distributing data across multiple nodes. As additional commodity resources are added, system performance can increase, enabling enterprises to maintain fast and reliable application responses. This approach allows organizations to scale performance in a predictable manner, ensuring an improved user experience without the overhead and complexity typically associated with manual sharding in traditional databases.
High Availability:
Many NoSQL databases are designed with distributed architectures that support data replication and fault tolerance. These systems aim to ensure high availability by allowing applications to continue performing read and write operations even if one or more nodes fail. While architectures may vary (some using master-less designs and others using primary-secondary models), NoSQL databases generally reduce the complexity found in traditional RDBMS setups and improve system reliability.
Global Availability:
Distributed NoSQL databases can automatically replicate data across multiple servers, data centers, or cloud regions. This replication minimizes data access latency and ensures consistent application performance for users located in different geographical regions. Additionally, automatic replication reduces the need for manual configuration and maintenance common in RDBMS, allowing operations teams to focus on other business-critical tasks.
Flexible Data Modeling:
NoSQL databases provide flexible and dynamic data models that allow developers to store and manage structured, semi-structured, and unstructured data. Application developers can choose data types and query mechanisms that best suit the application’s requirements rather than being constrained by fixed database schemas. This flexibility simplifies application-database interaction and enables faster, more agile application development.
Reduced Management and Administration:
Despite significant advancements in RDBMS technology, traditional databases often require intensive involvement from database administrators (DBAs) for tasks such as scaling, schema management, and performance tuning. In contrast, NoSQL databases are built to automate data distribution, scaling, and replication. This results in lower administrative effort, reduced operational complexity, and improved performance efficiency.
RDBMS vs NoSQL
Aspect
RDBMS
NoSQL
Maturity & Expertise
Users know RDBMS well as it is old and many organizations use this database for the proper format of the data.
This is relatively new and experts in NoSQL are less as this database is evolving day by day.
User Interface Tools
User interface tools to access data is available in the market so that users can try with all the schema to the RDBMS infrastructure. This helps to interact with the data well and users will understand the data in a better manner.
User interface tools to access and manipulate data in NoSQL is very less and hence users do not have many options to interact with data.
Scalability & Performance
RDBMS scalability and performance faces some issues if the data is used. Servers may not run properly with the available load and this leads to performance issues.
It works well with high loads. Scalability is very good in NoSQL. This makes the performance of the database better when compared with RDBMS. A huge amount of data could easily be handled by users.
Joins
Multiple tables can be joined easily in RDBMS and this does not cause any latency in the working of the database. A primary key helps in this case.
Multiple tables cannot be joined in NoSQL as it is not an easy task for the database and does not work well with the performance of the database.
Availability & Consistency
The availability of the database depends on the server performance and it is mostly available whenever the database is open. The data provided is consistent and doesn't confuse users.
Though the databases are readily available, consistency provided in some databases is less. This results in the performance of the database and users should check the availability often.
Data Analysis
Data analysis and querying can be done easily with RDBMS even though the queries are complex. Slicing and dicing can be done with the available data to make a proper analysis of the data given.
Data analysis is done also in NoSQL, but it works well with real-time data analytics. Reports are not done in databases, but if the application has to be built, then NoSQL is the solution for the same.
Document Storage
Documents cannot be stored in RDBMS because the data in the database should be structured and in proper format to create identifiers.
Documents can be stored in the NoSQL database as this is unstructured and not in rows and columns format.
Partitions & Key-Value Pairs
Partitions cannot be created in a database. Key value pairs are needed to identify the data in particular format if used in the schema database.
Partitions can be created in a database easily and key-value pairs are not needed to identify the data in the source. Software as a service can be integrated with NoSQL.
Database Type
RDBMS is called a relational database.
NoSQL is called a distributed database.
Scaling Direction
RDBMS is scalable vertically (adding more power to existing server - CPU, RAM, storage).
NoSQL is scalable horizontally (adding more servers to distribute the load).
Maintenance
Maintenance of RDBMS is expensive as manpower is needed to manage the servers added in a database.
NoSQL is mostly automatic and does some repairs on its own.
Examples
MySQL, Oracle, SQL Server, etc.
IBM Domino, Oracle NoSQL, Apache HBase, etc.
Types of NoSQL Databases
1. Document-Based
Document-based NoSQL database is designed to store and retrieve data in a semi-structured format known as documents. Each document represents a single entity and can be stored in various formats like JSON, BSON, XML, etc. Each document has a set of field and value pair. The values might be of any types such as text, image, boolean, arrays, etc. Document-based databases are suitable for unstructured or rapidly evolving data.
Examples:
MongoDB – It is a widely used document database known for its flexibility and scalability. It stores data in BSON format (Binary JSON Format).
Couchbase – is a NoSQL database that combines key-value and document store concepts.
Apache CouchDB – CouchDB is an open-source document database that stores data in JSON format.
2. Key-Value Stores
It is a type of NoSQL database that stores data as a collection of key-value pairs. In this model, each piece of data is associated with a unique key, and the database retrieves or updates the value based on this key. Key-Value Stores are known for their simplicity, high scalability, and fast data access.
Examples:
Redis – Redis is an in-memory key-value store known for its high performance and versatility.
Riak – Riak is a distributed key-value store designed for high availability and fault tolerance.
DynamoDB – is a fully managed key-value store service provided by Amazon Web Services (AWS).
3. Wide-Column Stores
Wide-column NoSQL databases store data in tables with rows and columns similar to RDBMS, but names and formats of columns can vary from row to row across the table. Wide-column databases group columns of related data together. A query can retrieve related data in a single operation because only the columns related to the query are retrieved. In an RDBMS, the data would be in different rows stored in a different place on disk, requiring multiple disk operations for retrieval.
Examples:
Apache Cassandra – is a highly scalable, distributed wide-column store designed for handling large amounts of data across many servers.
Apache HBase – is an open-source, distributed wide-column store built on top of Hadoop for real-time read/write access.
ScyllaDB – is a high-performance wide-column store compatible with Apache Cassandra but optimized for lower latency.
4. Graph-Based
Graph-based databases use graph structures to represent and store data. In graph-based databases, data is modeled as vertices (nodes) and edges (relationships), which allows for efficient representation and querying of highly interconnected data.
Examples:
Amazon Neptune – is a fully managed graph database service provided by Amazon Web Services.
JanusGraph – is an open-source distributed graph database built on Apache Cassandra.
OrientDB – is a multi-model graph database that also supports document and key-value models.
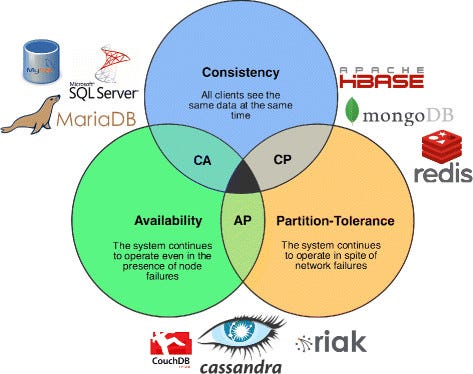
The CAP Theorem
CAP theorem is a theoretical framework which stands for Consistency, Availability, and Partitioning. CAP theorem helps to understand the limitation of NoSQL system. NoSQL cannot provide all three consistency, availability, and partitioning together. CAP states that we can only achieve at most two out of these three guarantees of database: consistency, availability, and partition tolerance.
Consistency: Every node of database has exactly same information at a given time. However, not all NoSQL distributed database nodes can provide it. They provide 'eventual consistency' i.e. while at one point the cluster may not be consistent, it will eventually be so.
Availability: Ability of database to be always available no matter what happens. A highly available database is usually one that has replicas in multiple geographical zones, and if some nodes aren't available, data will be accessible through one of it's other replicas without gurantee that it contains most recent version of data.
Partition Tolerance: Having ability to support broken links within the cluster in database in which it is distributed. The system continues operating despite network failure. Messages between nodes may be lost or delayed in network failures. If the database is partition tolerance, it still work despite the sudden lack of some of it's nodes.
Fig: Cap Theorem
Classification
In practical terms, this theorem has led to the classification of distributed systems into following three categories:
CP Systems: These systems prioritize consistency and partition tolerance over availability. They ensure that all nodes have consistent data but may sacrifice availability during network partitions.
Example: MongoDB .
AP Systems: These systems prioritize availability and partition tolerance over consistency. They provide high availability and partition tolerance but may allow for temporary inconsistencies in data.
Example: Apache Cassandra.
CA Systems: These systems prioritize consistency and availability but sacrifice partition tolerance. They operate as a single centralized system and do not tolerate network partitions.
Example: Traditional database running a single data center.
Big Data
Big Data refers to large and complex sets of data that are difficult to process and analyze using traditional methods. It is characterized by its volume, variety, and velocity. The volume refers to the massive amount of data generated, variety refers to the diverse types and formats of data, and velocity signifies the high speed at which data is generated.
Big Data offers immense value as it provides organizations with insights, patterns, and trends that were previously challenging to uncover. By analyzing large and diverse data sets, organizations can make data-driven decisions, optimize processes, detect anomalies, and gain a competitive advantage.
To process and analyze Big Data, various tools and techniques have emerged, such as Hadoop, Apache Spark, NoSQL databases, and MapReduce.
Characteristics of Big Data: 3V Model
The 3 V’s of Big Data describe the main characteristics of big data and explain why it is difficult to manage using traditional systems.
Volume refers to the extremely large amount of data generated from various sources such as social media platforms, online transactions, sensors, mobile devices, and multimedia content. This data is produced in terabytes and petabytes, which makes storage and processing a major challenge for conventional databases.
Velocity refers to the speed at which data is generated, collected, and processed. In today’s digital world, data is created continuously and often needs to be analyzed in real time or near real time, such as in online banking, stock markets, and live streaming services.
Variety refers to the different forms of data available. Big data is not limited to structured data stored in tables, but also includes semi-structured data like XML and JSON files, and unstructured data such as emails, text messages, images, audio, and videos. Together, these three V’s explain the complexity and importance of big data in modern information systems.
Map Reduce
MapReduce is a programming model and a computational algorithm used for processing and analyzing large volumes of data in a distributed computing environment. It was developed by Google to address the challenges of processing a Big Data efficiently across multiple machines in a cluster.
The MapReduce model divides a complex computational task into two main phases: the Map phase and the Reduce phase. The Map phase divides the input data into smaller portions and processes independently in multiple nodes, with each node applying a map function and generating intermediate key-value pairs. In the Reduce phase, the key-value pairs are sorted and processed by a reduce function. The reduce function performs a specific computation on these pairs and generates the final output.
Hadoop
Hadoop is an open-source framework that provides a distributed computing environment for storing and processing large volumes of data. It was created by the Apache Software Foundation and is designed to handle Big Data challenges.
Hadoop consists of two core components: Hadoop Distributed File System (HDFS) and MapReduce. HDFS allows data storage and handles large data sets by dividing them into smaller blocks. MapReduce enables parallel processing by dividing data into chunks, processes them, and combines the result.
Transperency in Distributed Databases
Transparency in a distributed database system refers to the property that hides the complexity of data distribution from users and application programs. The users should be able to access and manipulate data as if it were stored in a single, centralized database, without needing to know where the data is located, how it is fragmented, or how it is replicated across different sites. Transparency improves usability, simplifies application development, and allows the system to manage distribution-related issues internally.
Types of Transparencies in Distributed Databases
Location Transparency:
Location transparency ensures that users do not need to know the physical location of the data. Data can be accessed using the same name regardless of the site where it is stored. If data is moved from one location to another, applications remain unaffected.
Fragmentation Transparency:
Fragmentation transparency hides the way a database is divided into fragments. Whether data is horizontally fragmented, vertically fragmented, or mixed, users and applications can access the data as if it were stored as a single logical table.
Replication Transparency:
Replication transparency conceals the existence of multiple copies of data stored at different sites. The system automatically selects the appropriate copy for access and ensures consistency among replicas.
Concurrency Transparency:
Concurrency transparency ensures that simultaneous transactions executed at different sites do not interfere with each other. Users are unaware of concurrent operations, and the database maintains correctness and consistency.
Failure Transparency:
Failure transparency allows the system to continue operating even when site or network failures occur. The system automatically recovers from failures without affecting users or requiring manual intervention.
Performance Transparency:
Performance transparency ensures that system performance is optimized automatically as the system load or configuration changes. Users are not required to modify applications when performance-related adjustments are made.
Scaling Transparency:
Scaling transparency allows the distributed database system to expand by adding new sites or resources without requiring changes to existing applications or database structure.