The Enhanced ER (EER) Model is an extension of the traditional ER model used to represent complex database requirements. The ER modeling concepts are not sufficient for representing new database applications which are more complex than traditional applications. To model modern complex systems—such as databases for engineering design and manufacturing (CAD, CAM), telecommunications, GIS, etc.—it is not enough with the ER model.
Thus, modeling of such systems can be made easy with the help of the Enhanced ER model. The enhanced ER model includes all of the concepts introduced by the ER model. Additionally, it includes the concepts of:
Subclasses and Superclasses
Specialization and Generalization
Category (or Union)
Aggregation
Features of EER Model
EER creates a design more accurate to database schemas.
It reflects the data properties and constraints more precisely.
It includes all the modeling concepts of the ER model.
Diagrammatic techniques help for displaying the EER schema.
It includes the concepts of specialization and generalization.
It is used to represent the collection of objects that is a union of objects of different entity types.
Subclass and Super Class
Super class is an entity type that has a relationship with one or more subtypes. An entity cannot exist in the database merely by being a member of any super class. For example, a Shape super class is having subgroups as Square, Circle, and Triangle.
Subclass is a group of entities with unique attributes. A subclass inherits properties and attributes from its super class. For example, a Square, Circle, and Triangle are the subclasses of the Shape super class.
Fig: Subclass and Super Class
Because an entity in the subclass represents the same real-world entity from its super class, it should possess values for its specific attributes as well as the values of its attributes as a member of the super class.
We say that an entity that is a member of a sub-class inherits all attributes of the entity as a member of the super class. The entity also inherits all the relationships in which the super class participates. A sub-class with its own specific (or local) attributes and relationship, together with all the attributes and relationships it inherits from the super class, can be considered an entity type in its own right.
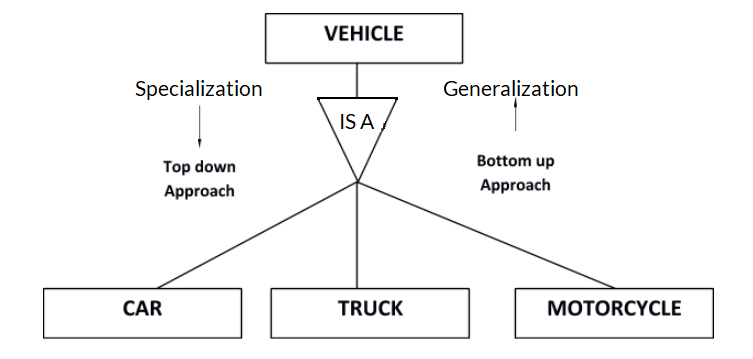
Specialization is a process that defines a group entities which is divided into sub-groups based on their characteristics. It is a top-down approach in which one higher entity can be broken down into two lower level entities.
Fig: Specialization and Generalization
Generalization is the process of generalizing the entities which contains the properties of all the generalized entities. It is a bottom-up approach in which two lower level entities combine to form a higher level entity. It is the reverse process of specialization.
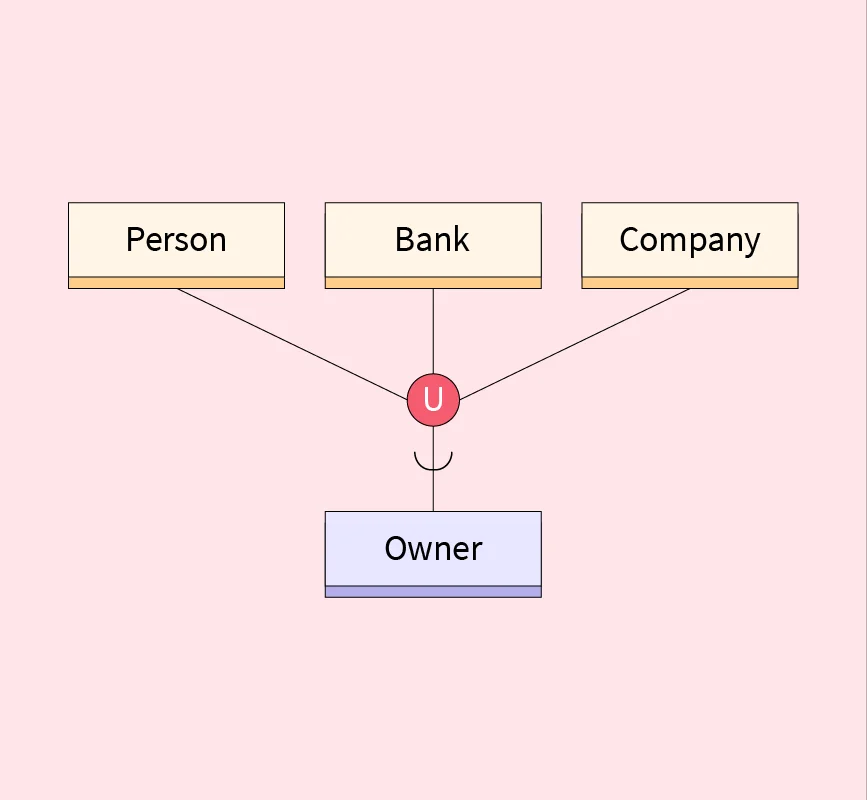
Category or Union
It is possible that single super class/subclass relationship has more than one super class representing distinct entity types. In this case, the subclass will represent a collection of objects that is (a subset of) the UNION of distinct entity types. We call such a subclass a union type or a category.
Fig: Category or Union
Category represents a single super class/subclass relationship with more than one superclass, whereas non-category super class/subclass relationship always have a single superclass. It can be a total or partial participation.
Aggregation
Aggregation is a process that represents a relationship between a whole object and its component parts. Using aggregation, we can express relationships among relationships. Aggregation shows "has-a" or "is part of" relationship between entities where one represents the "whole" and other "part". It abstracts a relationship between objects and viewing the relationship as an object. It is a process when two entities and relationship with these entities is treated as a higher-level single entity set.
Fig: Aggregation
Constraints on Specialization and Generalization
There are two constraints that may apply to specialization and generalization called participation constraints and disjoint constraints.
Participation constraint.
Participation constraint determines whether every member in the superclass must participate as a member of the subclass. It may be mandatory (total specialization/generalization) or optional (partial specialization/generalization). A superclass-subclass relationship with mandatory participation specifies that every member in the superclass must also be a member of the subclass. To represent mandatory participation, 'mandatory' is placed in curly brackets below the triangle that points towards the superclass.
A superclass-subclass relationship with optional participation specifies that a member of a superclass need not belong to any of its subclasses. To represent optional participation, 'optional' is placed in curly brackets below the triangle that points towards the superclass.
Disjoint constraints.
Disjoint constraint describes the relationship between member of the subclass and indicates whether it is possible for a member of superclass to be a member of one or more than one subclass. The disjoint constraint only applies when a superclass has more than one subclass.
If the subclasses are disjoint, then entity occurrence can be a member of only one of the subclasses. To represent a disjoint superclass-subclass relationship, 'or' is placed next to the participation constraint within the curly brackets.
If subclass of specialization and generalization are not disjoint, called non-disjoint or overlapping, then any entity occurrence may be a member of one or more than one subclass. To represent a non-disjoint superclass-subclass relationship, 'and' is placed next to the participation constraint within the curly brackets.
Converting ER and EER Model to Relational Model
1. Mapping Strong Entity Sets
Create table for each of the strong entity.
Entities attributes should become fields of tables with their respective data types.
Declare key attribute of strong entity set as a primary key of the table.
2. Mapping weak entity sets
A weak entity set does not have its own primary key and always participate in one-to-many relationship with other owner entity set and has total participation.
Create table for weak entity set,
Add all its attributes to table as fields,
Add the primary key of the identifying entity set
Declare all foreign key constraints.
3. Mapping of binary one-to-one relationship type
For constructing table from a binary one-to-one relationship, we set primary key of any one of the entity set as foreign key. It is better to include foreign key into the entity set with total participation in the relationship.
4. Mapping of binary one-to-N relationship type
For binary one-to-many relationship, identify the relation that represent the participating entity type at N side of the relationship type and then include primary key of one side entity set into many sides entity set as foreign key. Separate relation is created for relationship set only when the relationship set has its own attributes.
5. Mapping of binary M-to-N relationship type
For a binary many-to-many relationship type, a separate relation is created for the relationship type. Primary key for each participating entity set is included as foreign key in the relation and their combination will form the primary key of the relation. Besides these simple attributes of the many-to-many relationship type or simple components of composite attribute is included as attributes of the relation.
6. Mapping of multivalued attributes
If an entity has multivalued attributes, separate relation is created with primary key of the entity set and multivalued attribute itself.
7. Mapping composite attributes
If an entity has composite attributes, no separate attribute column is created for composite attribute itself. Rather, attributes/columns are created for component attributes of the composite attribute.
8. Mapping of N-ary relationship type
For each N-ary relationship set, for N>2, a new relation is created. Primary keys of all participating entities are included in the relation as foreign key attributes. Besides these, all simple attributes of N-ary relationship set or simple components of composite attributes are included as attributes of the relation.
9. Mapping of specialization and generalization
To construct relational tables from given EER diagram with specialization and generalization, we set primary key of the superclass to their subclass as their foreign key. If subclass are disjoint and complete, then relation for subclass entity set includes all attributes of superclass entity set and all of its attributes.
10. Mapping aggregation
In relational model seperate relation is created for this relationship set and relation contains primary key of associated entity set and relationship set and it's own attributes, if any.
SQL and Advanced Features
Structure Query Language is a database query language used for storing and manipulating data in Relational DBMS.
SQL Features
DDL: CREATE, DROP, ALTER, RENAME
DML: INSERT, UPDATE, DELETE, SELECT
DCL: GRANT, REVOKE
TCL: COMMIT, ROLLBACK, SAVEPOINT
Advanced SQL Features
SQL UNION:
The purpose of the SQL UNION query is to combine the results of two queries together while removing duplicates.
SELECT id FROM tableA
UNION
SELECT id FROM tableB;
SQL UNION ALL:
The purpose of the SQL UNION ALL command is to combine the results of two queries together without removing any duplicates.
SELECT id FROM tableA
UNION ALL
SELECT id FROM tableB;
SQL INTERSECT:
The purpose of this command is to combine the result of two SQL statements and returns only data that are present in both SQL statements.
SELECT id FROM tableA
INTERSECT
SELECT id FROM tableB;
SQL MINUS:
The MINUS command operates on two SQL statements. It takes all the results from the first SQL statement and then subtracts out the ones that are present in the second SQL statement to get the final result set. If the second SQL statement includes results not present in the first SQL statement, such results are ignored.
SELECT id FROM tableA
MINUS
SELECT id FROM tableB;
SQL LIMIT:
The LIMIT command restricts the number of results returned from a SQL statement.
SELECT * FROM tableA
LIMIT 5;
File Structures
A file is a sequence of records stored in binary format. A file structure is a combination of representation for data in files. It is a collection of operations for accessing the data. It enables application to read/write and modify data. The main goal of developing file structure is to minimize the number of trips to the disk in order to get desired information.
File organization
It defines how file records are mapped into the disk blocks. We have four types of file organization to organize the file records.
Heap file organization.
When a file is created using heap file organization, the operating system allocates memory area to the file without any further accounting details. File records can be placed anywhere in that memory area. It is the responsibility of the software to manage the records. Heap file does not support any ordering, sequencing, or indexing on its own.
Sequential file organization.
Every file record contains a data field attribute to uniquely identify that record. In sequential file organization, records are placed in the file in some sequence and order based on the unique field or the source key.
Hash file organization.
Hash file organization uses a hash function computation on some fields of the records. The output of the hash function determines the location of the disk block where the records are to be placed.
Clustered file organization.
Clustered file organization is not considered good for large database. In this mechanism, related records from one or more relations are kept in the same disk block. That is, the ordering of record is not based on primary key or source key.
B+ tree file organization.
It is a tree-like structure to store records in a file. It uses the same concept of key index where the primary key is used to sort the record. For each primary key, the value of the index is generated and mapped with the record.
The B+ tree is similar to a binary search tree, but it can have more than two children. In this method, all the records are issued only at the leaf node. Intermediate nodes act as a pointer to the leaf node. They do not contain any records.
Hashing
In large databases, it is not possible to search all the indexes to obtain the required data. Hashing is an effective technique to calculate the direct location of the data record on the disk without using sequential index structure which results decrease in data retrieval time.
Hashing uses a hash function with source keys to its parameters to generate the address of data record. A hash function returns a value which is nothing but the address of the desired data block. The memory location address where these records are stored is known as data bucket or data block. A bucket is considered a unit of storage. A bucket typically stores one complete disk block which in turn can store one or more records.
Hashing is not favourable when the data is organized in some ordering and a queries require a range of data. When data is discrete or random, hashing performs best.
The hashing can be further divided into two types:
Static Hashing.
In static hashing, the hash function always computes the same address when a source key value is given. For instance, if the mod-4 hash function is used, then only five values are generated. For that function, the output address must always be the same at all times. The number of buckets given remains unchanged.
Dynamic Hashing.
The issue with the static hashing is that if the size of the database grows or shrinks, it does not dynamically expand or shrink. Dynamic Hashing offers a process through which the data buckets are dynamically and on-demand added and removed. Dynamic Hashing is referred to as extended hashing as well. In dynamic hashing, the hash function is created to produce a large number of values and only a few are initially used.
Indexing
Indexing is used to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed. The index is a type of data structure having only two columns. The first column comprises a copy of the primary or candidate key of a table. Its second column contains the state of pointers for holding the address of the disk block where the specific key value is stored. An index takes a search key as input and efficiently returns a collection of matching records.
Advantages of Indexing:
Better performance of queries
Fast searching from the database
Fast retrieval of data
Increased performance in Select query
Disadvantages:
Indexing takes more space
Decreased performance in Insert, Delete, and Update query
Types of Indexing:
Primary Index:
Primary index is an order file which is fixed, having size with two fields. The first field is the same as primary key and second field is pointed to that specific data block. In the primary index, there is always one-to-one relationship between entries in index table. As primary keys are stored in the sorted order, the performance of the searching operation is quite efficient.
It can be divided into two types:
Dense Indexing:
In a dense indexing, a record is created for every sort key value in the database. This helps to search faster but needs more space to store index record. In this indexing method, records contain source key value and points to the real record on the disk.
Sparse Indexing:
It is an index record that appears for only some of the values in the file. Sparse index helps to resolve the issues of dense indexing. In this method of indexing technique, a range of index columns stores the same data block address, and when data needs to be retrieved, the block address will be fixed. However, a sparse index stores index records for only some search key values. It needs less space, less maintenance overhead for insertion and deletions, but it is slower compared to dense index for locating records.
Secondary indexing:
Secondary index can be generated by a field which has unique value for each record and it should be a candidate key. It is also known as non-clustering index. This two-level database indexing technique is used to reduce the mapping size of the first level. For the first level, a large range of numbers is selected because of this, the mapping size always remains small.
Clustered indexing:
In a clustered index, records themselves are stored in the index and not pointers. Sometimes the index is created on non-primary key columns which might not be unique for each record. In such a situation, two or more columns are grouped to get unique values and create an index which is called clustered index. It helps to identify the record faster. The records which have similar characteristics are grouped and indexes are created for these groups.
Multi-level indexing:
Multi-level indexing is created when a primary index does not fit in memory. In this type of indexing method, the number of disk accesses can be reduced. To sort any record and keep it on a disk as a sequential file and create a sparse base on that file.
Indexing vs Hashing
Feature
Indexing
Hashing
Definition
A technique that allows to quickly retrieve records from a database file.
A technique that allows to search the location of desired data on disk.
Primary Purpose
Used to increase the performance of the database.
Used to retrieve items from the database faster.
Scalability
Does not work well for large databases.
Works well for large databases.
Mechanism
Uses a data reference that holds the address of a disk block with the value corresponding to a key.
Uses a mathematical function called a Hash function to calculate the location.
Types
Primary, Secondary, Cluster, and Multi-level indexing.
Static and Dynamic hashing.
Generalization vs Specialization
Feature
Specialization
Generalization
Approach
Top-down approach
Bottom-up approach
Schema Size
Size of schema gets increased
Size of schema gets reduced
Application
Applied to a single entity
Normally applied to a group of entities
Process
It is a process of creating subgroups within an entity set
It is a process of creating groups from various entity sets