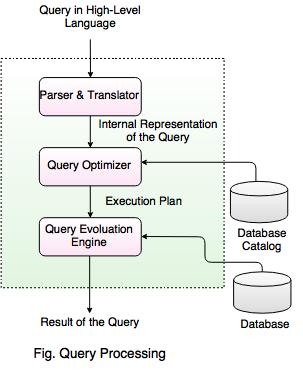
Query processing is the process of executing a database query or request for information. It is a process of extracting the data from a database.
The aims of query processing are:
To transform a query written in a high-level language, typically SQL, into a correct and efficient execution strategy expressed in a low-level language implementing the relational algebra, and
To execute the strategy to retrieve the required data.
Thus, query processing is the activities involved in parsing, validating; optimizing, and executing a query.
The steps involved in query processing are:
Parsing and Translaton
Optimization
Evaluation
Parsing and Translating the Query
The main work of query processor is to convert a query string into query objects, i.e. converting the query submitted by the user into a form understood by the query processing engine. It converts the source string into definite instruction.
The query parser must analyze the query language, i.e. recognizing and interpreting operators (AND, OR, NOT, +, - etc.), placing the operators into groups etc. The basic job of the parser is to extract the tokens, (for example, keywords, operators, operands, literals, strings, etc.), into their corresponding internal data elements, (i.e. relational algebra operations and operands) and structures,( i.e. query tree, query graph.) Parser also verifies the validity and syntax of the query string.
Optimizing the Query
In this stage, Query Optimizer tries to find the most efficient way of executing a given query by considering the possible plans. It maximizes the performance of a query. It portrays the query plans as a tree, results flowing from bottom to top. Query processor applies rules to the internal data structures of the query to transform these structures into their equivalent but more efficient representation. Rules may be based on various mathematical models and heuristics.
Evaluating the query
The final step in processing a query is the evaluation phase. An evaluation plan tells precisely the algorithm for each operation along with the coordination among the operations. The best evaluation plan that a user generates by the optimization engine is selected and then executed. There may exist various methods for executing the same query. The evaluation plan comprises of a relational algebra tree, providing information at each node for each table along with the implementation methods to be implemented for each relational operator.
Example of Query Processing
Consider the SQL Query
SELECT name, address
FROM Student
WHERE age <= 25;
This query can be translated into either of the following relational-algebra expressions:
σ age<=25 (∏ name, address (Student))
∏ name, address (σ age<=25 (Student))
This can be represented as either of the following query trees:
σ age<=25
↑
∏ name, address
↑
Student
or
∏ name, address
↑
σ age<=25
↑
Student
Fig: Query Tree
After parsing and translation into a relational algebra expression, the query is than transformed into a form, usually query tree or query graph that can be handled by the optimization engine.
The optimization engine then performs various analyses on the query data, generating a number of valid evaluation plans. From there, it determines the most appropriate evaluation plan to execute.
After the evaluation plan has been selected, it is passed into the DBMS's query-execution engine, also referred to as the runtime database processor, where the plan is executed and the results are returned.
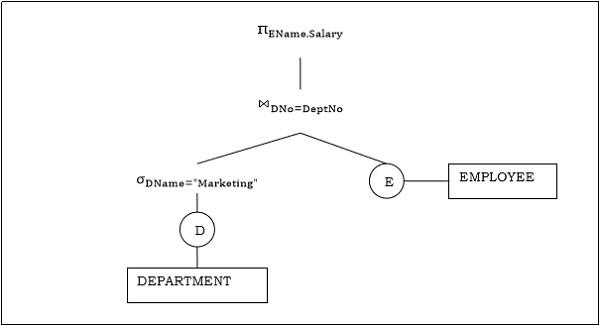
Query Trees
Query trees are a hierarchical representation of the steps and operations involved in executing a database query. They are used in query processing to outline the logical and physical operations required to retrieve the desired data from the database. A query tree is typically represented as a tree-like structure with each node representing an operation or transformation applied to the data. The nodes are connected by edges that indicate the flow of data between operations. The root node represents the final result of the query, and the leaf node represents the base table or data source being accessed.
Fig: Query Tree
Need of Query Trees
Visualization and Understanding
Query trees provide a visual representation of the query execution plan, making it easier to understand and analyze the steps involved in query processing.
Query optimization
By representing the query execution plan as a tree, the optimizer can efficiently explore and evaluate various plan alternatives to find the most efficient one.
Execution order and data flow
Query trees define the order in which the operations are performed and how data flows between them.
Query plan caching and reuse
Query trees can be cached and reused for similar queries with different parameter values. This improves query performance by avoiding recomputation.
Query Optimization
Query optimization refers to the process of improving the performance and efficiency of database queries. It involves the most effective way to retrieve data. The primary goal of query optimization is to minimize the execution time and resource consumption of a query, such as CPU usage, disk I/O, and network traffic.
Need of Query Optimization:
Improved Performance: The query optimization helps improve the performance of database systems by reducing the execution time of queries.
Resource Utilization: Query optimization aims to minimize resource consumption, such as CPU usage, disk I/O, and network traffic.
Cost Reduction: Query optimization helps reduce costs by minimizing the resources used and improving overall efficiency of query execution.
Scalability: Optimization techniques such as indexing, caching, and parallel processing help ensure the system can handle growing workloads and provide consistent performance.
Complex Query Support: Query optimization techniques consider various factors, such as query rewriting, join ordering, and index selection, to generate effective execution plans for complex queries.
Application Responsiveness: It provides faster responses, leading to better user experience.
Heuristics for Query optimization
Heuristics refer to rules or guidelines that guide the decision-making process of the query optimizer. Heuristics are practical techniques based on general principles and assumptions about the behavior of a database system and the characteristics of queries and data. They are not guaranteed to always find the optimal solution but aim to find good solutions with a reasonable amount of time and resources.
Heuristic rules
They are used as an optimization technique to modify the internal representation of query. Usually, these rules are in the form of a query tree or a query graph data structure to improve its performance. One of the main heuristic rules is to apply SELECT operation before applying the JOIN or other binary operation. SELECT and PROJECT reduces the size of the file and hence should be applied before JOIN or other binary operation. Heuristic queries optimizer transform the initial query tree into final query tree using equivalence transformation rules.
Query Optimization Strategies
1. Cost Based Optimization
Cost-based optimization is a process of selecting lower-cost mechanism and it is based on the cost of the query.
It is based on the cost of the query that to be optimized.
The query can use a lot of paths based on the value of indexes, available sorting methods, constraints, etc.
The aim of query optimization is to choose the most efficient paths of implementing the query at the possible lowest minimum cost in the form of an algorithm.
The cost of executing the algorithm is to be provided by the query optimizer so that the most suitable query can be selected for an operation.
The cost of an algorithm also depends upon the cardinality of the input.
Cost of the query
Cost of query is the time taken by the query to hit the database and return the result. It involves query processing time, i.e. time taken to parse and translate the query, optimize it, evaluate, execute, and return the result to the user.
Query cost considers the number of different resources, for example, the number of disk accesses, the number of disk block transfers, the size of the table, time taken by CPU for executing the query. The time taken by CPU is negligible in most systems when compared with the number of disk accesses.
If we consider the number of block transfers the main component in calculating the cost of the query, it would include more subcomponents. Those are
Rotational latency - time taken to bring and spin the required data under the read-write head of the disk
Seek time - time taken to position the read-write head over the required track or cylinder,
Sequential I/O - reading data that are stored in contiguous blocks of disk,
Random I/O - reading data that are stored in different blocks that are not contiguous.
For simplicity, we just use the number of block transfers from disk and the number of seeks as the cost measure of query evaluation plan.
Suppose a query need to seek S times to fetch a record and there are b blocks needed to be returned to the user. The disk I/O cost is calculated as below. Query cost = b * tT + S * tS
where ,
b = block transfers,
S = seeks
tT = time to transfer one block,
ts = time for one seek.
2. Heuristic-based Optimization
Heuristic optimization transforms the query tree by using a set of rules, heuristics, that typically, but not in all cases, improve execution performance. Some common heuristic rules are:
perform selection early, reduces the number of tuples;
perform projection early, reduces the number of attributes;
perform most restrictive selection and join operations, that is, with smallest result size, before other a similar operations.
Initially, query tree from SQL statement is generated, query tree is transformed into more efficient query tree via a series of tree modifications, each of which fully reduces the execution time. A single query tree is involved at last.
3. Semantic-based optimization.
This strategy uses constraints specified on the database schema, such as unique attributes and other more complex constraints, in order to modify one query into another query that is more efficient to execute.
Consider the following SQL query.
SELECT e.lname, m.lname
FROM EMPLOYEE as e, EMPLOYEE as m,
WHERE e.super_ssn = m.ssn
AND e.salary > m.salary.
This query retrieves the names of employees who earn more than their supervisors. Suppose that we had a constraint on the database schema that stated that no employee can earn more than his or her direct supervisor. If the semantic query optimizer checks for that existence of this constraint, it does not need to execute the query at all because it knows that the result of the query will be empty. This may save considerable time if the constraint checking can be done efficiently. However, sourcing through many constraints to find those that are applicable to the given query and that may semantically optimize it can also be quite time-consuming.
Choice of Query Execution Plans
also referred as Query Evaluation Plans
The process of query execution plans refers to the process of selecting the most efficient and effective plan for executing a database query in a relational database management system. When a query is submitted to a database, the database engine analyzes the query and generates multiple possible execution plans. The goal is to select a plan that minimizes the overall cost of executing the query, which typically involves factors such as disk I/O speed, CPU utilization, and memory consumption.
The optimizer aims to estimate the cost of each plan and select the one with the lowest estimated cost. Factors that influence the choice of query execution plan include table and index statistics, database configuration, shading, available system resources, join condition, etc. By choosing the optimal execution plan, database systems can significantly improve query performance, reduce resource wastage, and provide faster response times for users.
Heuristic Query Optimization vs Cost Based Query Optimization
Feature
Heuristic Query Optimization
Cost-Based Query Optimization
Approach
Relies on predefined rules or heuristics based on common knowledge and intuition.
Considers actual cost and statistical information; based on estimated cost and statistical analysis.
Implementation
Simple and easy to implement.
More complex to implement and maintain.
Adaptability
Does not adapt well to changing data or query workloads.
Can adapt to changing workload based on updated stats.
Data Dependency
Independent of accurate statistical data.
Relies heavily on accurate statistical data.
Overhead
Low computational overhead.
Higher computational overhead due to cost estimation.
Plan Exploration
Limited exploration of alternative plans.
Explores various plans and join orders.
Query Processing vs Query Optimization
Feature
Query Processing
Query Optimization
Definition
The overall range of activities involved in extracting data from a database.
The specific phase within query processing that aims to find the most efficient execution plan.
Scope
Includes parsing, translation, optimization, and final evaluation/execution.
Specifically focuses on transforming a query into an equivalent form that minimizes cost.
Goal
To convert a high-level query (SQL) into a result set for the user.
To minimize resource usage (CPU, I/O) and reduce total execution time.
Input
A high-level language query (e.g., SQL) submitted by the user.
An internal representation (like relational algebra) generated after parsing.
Output
The final result data retrieved from the database.
An optimized Query Execution Plan passed to the evaluation engine.
Process Steps
- Parsing & Translation, Optimization, Evaluation
Generating alternative plan, Estimating costs, Choosing the best plan